深度学习 学习笔记
BP算法(Back Propagation)
BP算法被译为(误差)反向传播算法,它主要的作用是根据误差调整神经网络中每个参数,使误差更小。BP算法是训练神经网络中最重要的算法,可以说,没有BP算法,就没有深度学习的今天。
BN算法(Batch Normalization)
为什么:当进行神经网络训练时,需要使用BP算法对某一层的参数进行更新。但是更新后可能会使这一层的输入分布发生变化。这里的分布发生变化应该是输入的统计分布发生变化,即主要变化均值和方差。输入分布发生变化,再次更新,参数又要变;参数一变,分布也要变……这样下去没完没了,模型训练的速度会急速下降,甚至导致不收敛的问题。所以需要引入批归一化(BN)来解决参数和分布“互相追逐”的问题。
是什么:BN最主要的作用是将输入数据转化为均值为0,方差为1的分布。
怎么做:

BN算法有如下的好处。
- 使用BN后可以使用更大的学习率,训练过程更加稳定,极大提高了训练速度。
- 可以将bias置为0,因为Batch Normalization的Standardization过程会移除直流分量,所以不再需要bias。
- 对权重初始化不再敏感,通常权重采样自0均值某方差的高斯分布,以往对高斯分布的方差设置十分重要,有了Batch
- Normalization后,对与同一个输出节点相连的权重进行放缩,其标准差σ也会放缩同样的倍数,相除抵消。
- 对权重的尺度不再敏感,理由同上,尺度统一由γ参数控制,在训练中决定。
- 深层网络可以使用sigmoid和tanh了,理由同上,BN抑制了梯度消失。Batch Normalization具有某种正则作用,不需要太依赖dropout,减少过拟合。
总之,用了BN和BP后训练效果会更好,目前没有看到这种算法对FPGA移植有什么帮助
模型轻量化设计
模型轻量化设计可以在损失轻微精度的背景下大幅减轻模型的数据量,提高运算速度。但是模型轻量化设计的前提是已经有一个训练好的模型。对于冯诺依曼计算机而言,对模型进行轻量化处理可以明显减少对内存的使用,减少内存的访问带宽需求,CPU命中Cache的概率也会显著提高。
这里有一句不明白,后续有时间再了解:轻量化对 Batch-norm,ReLU,Elementwise-sum 这种内存约束(Memory Bound)的Element wise来说效果更明显。
量化可以在训练时引入(QAT-Quantization aware training),也可以在训练后对模型进行量化(PTQ,Post training quantization)。QAT略微复杂,但是损失的精度较小。PTQ做法简单,只不过相比于QAT要损失更多的精度。
量化分为非对称算法和对称算法。本质上就是FP32类型的数据映射到int-8或者uint-8的空间。
现有的模型使用的是定点小数
ap_fixed<16>,原理类似。
- 非对称算法:基本思想是通过收缩因子
和 将FP32张量的 min/max 映射到8-bit数据的 min/max ,同时不丢失原有的数据分布信息。
上式中的 round是进行四舍五入的函数。
- 对称算法:直接通过对称因子收缩。
YOLOv4 Tiny
Pytorch 实现
Darknet是一个轻量级的神经网络框架,同时是一个开源项目,可以在GitHub上找到,YOLO是Darknet的标志性应用之一。它是一种实时目标检测算法,能够在单次向前传播中检测图像中的多个对象,并输出它们的边界框和类别。Darknet本身就是用C语言写的。Darknet不仅限于目标检测,还支持图像分类、语义分割哼生成对抗式网络(GANs)等多种深度学习任务。
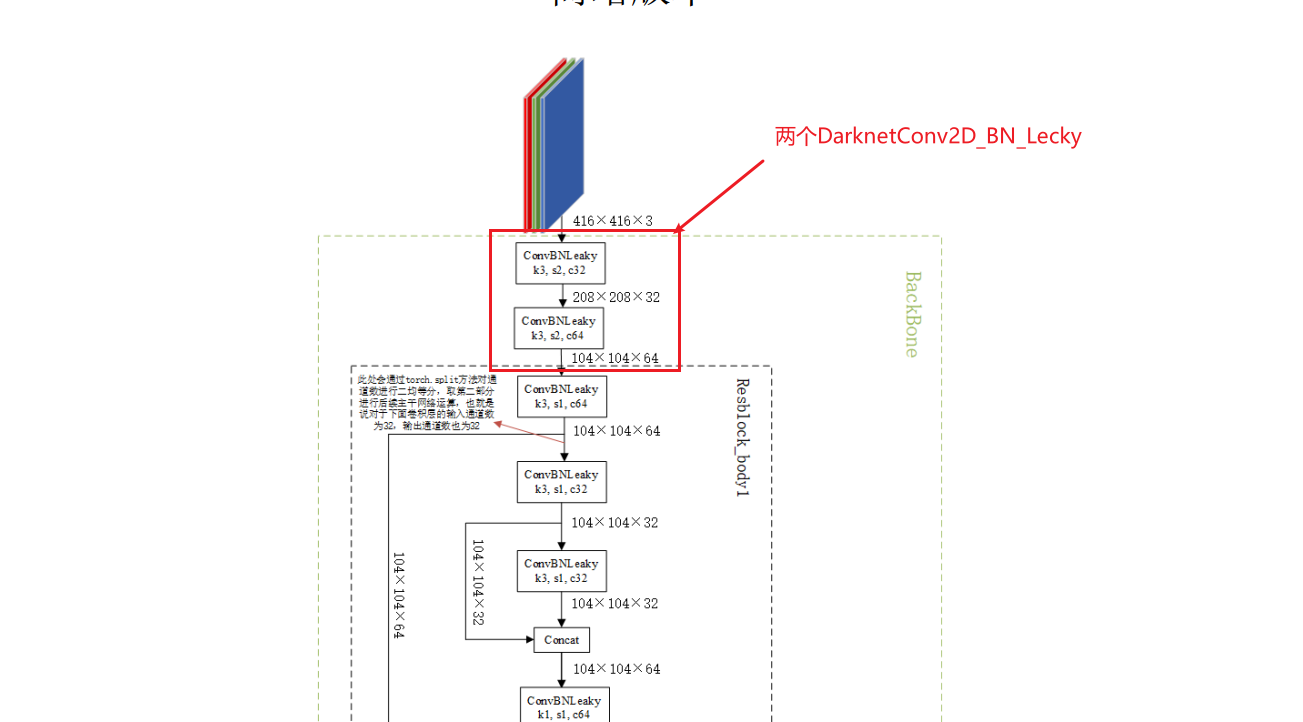
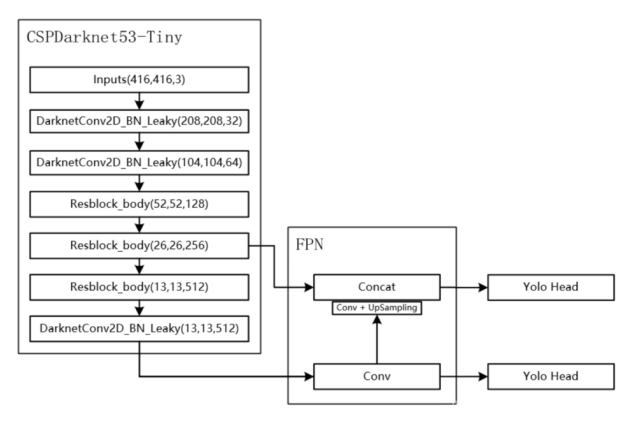
源码中的CSPdarknet是Darknet53的一种改进架构。
该网络中所有的卷积核大小都是3。
torch.nn中有一个非常常用的类Conv2D中有一个参数为dilition,意为膨胀。作用是卷积核的大小不变,dilitoin定义了两个输入像素之间的距离。下面的图定义了dilition=(2, 2)的情况。

1 | class BasicConv(nn.Module): |
让padding=kernel_size//2的目的是用步长
stride 的大小,来控制 OFM 的宽和高
是保持不变,还是缩放为原来的一半。当
stride=1时,宽高不变,当stride=2时,宽高变为原来的一半。
暂时不知道forward函数中的x是做什么的。
forward是模型的核心,它定义了数据的流动方向。在对象实例化的时候传入对应的参数会自动调用forward方法。(逆天,据说能实现是因为类中定义了__call__()方法,但是没有找到在哪写了这个方法,不知道怎么实现的)
1 | class Module(nn.Module): |
啥是attention?
About this Post
This post is written by Yun Zhang, licensed under CC BY-NC 4.0.